文字コードがShift JISかEUC-JPのどちらなのか判別する方法について。 およびC#による実装。
文字コードのマップ
下図の黄色の領域がShift JISの文字コードで取り得る範囲、青色の領域がEUC-JPの文字コードで取り得る範囲。 文字がこのどちらに属するか調べることで文字コードを判別する。 灰色の領域はASCII文字、緑色の領域はShift JIS、EUC-JPともに取り得る領域で、この範囲の文字では文字コードがどちらなのか判別できない。
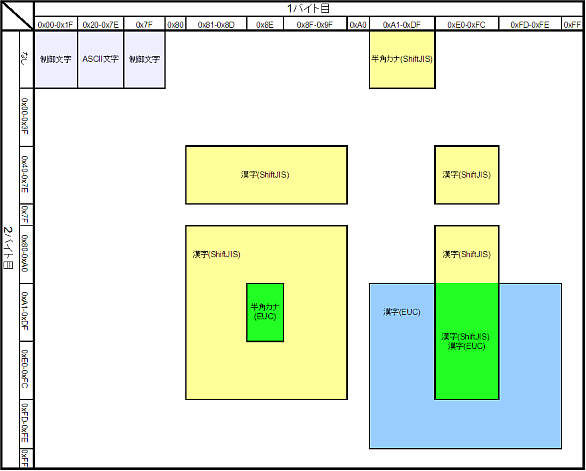
この図にはEUC-JPの3バイト文字は含まれていない。
C#での実装
ソースの概要
- ストリームの先頭から1バイトずつ読み込み、文字コードのマップに照らし合わせる
- 文字コードが判別出来た場合は、Shift JISかEUC-JPのEncodingを返す
- 文字コードが判別出来なかった場合はEncoding.ASCIIを返す
- EUC-JPの3バイト文字が含まれていた場合は考慮していない
Encoding JudgeCharacterEncoding(Stream stream)
{
BinaryReader reader = new BinaryReader(stream);
byte byteCount = 1; // 文字の1バイト目か、2バイト目か
byte lastByte = 0; // 直前の1バイト
while (-1 != reader.PeekChar()) {
// 1バイト読み込む
byte currByte = reader.ReadByte();
if (1 == byteCount) {
// 1バイト目について判定
if (0x00 <= currByte && currByte <= 0x7f) {
// ASCII文字(0x00〜0x7f)なので、2バイト目は無い
byteCount = 1;
}
else if (0x80 == currByte) {
// 制御文字なので、2バイト目は無い
byteCount = 1;
}
else if (0x81 <= currByte && currByte <= 0xa0) {
// 1バイト目が0x81〜0x9fの場合は、EUC-JP/Shift JISともに
// 2バイト文字である
byteCount = 2;
lastByte = currByte;
}
else if (0xa1 <= currByte && currByte <= 0xfc) {
// 1バイト目が0xa1〜0xfcの場合は、2バイト目をチェックしない
// 限り断定できない
byteCount = 2;
lastByte = currByte;
}
else if (0xfd <= currByte && currByte <= 0xfe) {
// 1バイト目が0xfd〜0xfeの場合は、EUC-JPの1バイト目と
// 断定出来る
return Encoding.GetEncoding("euc-jp");
}
else {
throw new Exception("あり得ない");
}
}
else if (2 == byteCount) {
// 2バイト目について判定
if ((0x8e == lastByte) &&
(0xa1 <= currByte && currByte <= 0xdf) )
{
// 1バイト目が0x8e、2バイト目が0xa1〜0xdfの場合、文字は
// EUC-JPの半角カナとShift JISの両方の可能性があるため、
// 断定出来ない。 次は1バイト目と見なして解析を続ける。
byteCount = 1;
continue;
}
else if ((0xe0 <= lastByte && lastByte <= 0xfc) &&
(0xa1 <= currByte && currByte <= 0xfc))
{
// 1バイト目が0xe0〜0xfc、2バイト目が0xa1〜0xfcの場合、
// 文字はEUC-JPとShift JISの両方の可能性があるため、断定
// 出来ない。 次は1バイト目と見なして解析を続ける。
byteCount = 1;
continue;
}
// ShiftJISの範囲に含まれるか判断する
if (0x81 <= lastByte && lastByte <= 0x9f) {
// 1バイト目が0x81〜0x9fの場合
if (0x40 <= currByte && currByte <= 0x7e) {
// 2バイト目が0x40〜0x7eならShift JIS
return Encoding.GetEncoding("Shift_JIS");
}
else if (0x80 <= currByte && currByte <= 0xfc) {
// 2バイト目が0x80〜0xfcならShift JIS
return Encoding.GetEncoding("Shift_JIS");
}
}
else if (0xa1 <= lastByte && lastByte <= 0xdf) {
// 1バイト目が0x1a〜0xdfの場合
if (0x8e != currByte && !(0xa1 <= currByte && currByte <= 0xfe)) {
// 2バイト目が0x8e、0xa1〜0xef以外の場合は、
// Shift JISの半角カナと断定できる
return Encoding.GetEncoding("Shift_JIS");
}
else {
// 上記の場合は、1バイト目はShift JISの半角カナだった
// 可能性がある。 次は1バイト目と見なして解析を続ける。
byteCount = 1;
continue;
}
}
else if (0xe0 <= lastByte && lastByte <= 0xfc) {
// 1バイト目が0xe0〜0xfcの場合
if (0x40 <= currByte && currByte <= 0x7e) {
// 2バイト目が0x40〜0x7eならShift JIS
return Encoding.GetEncoding("Shift_JIS");
}
else if (0x80 <= currByte && currByte <= 0xfc) {
// 2バイト目が0x80〜0xfcならShift JIS
return Encoding.GetEncoding("Shift_JIS");
}
}
// Shift JISの範囲に含まれない場合は、EUC-JPの範囲に
// 含まれるか判断する
if (0x8e == lastByte) {
// 1バイト目が0x8eの場合
if (0xa1 <= currByte && currByte <= 0xdf) {
// 2バイト目が0xa1〜0xdfならEUC-JP(半角カナ)
return Encoding.GetEncoding("euc-jp");
}
}
else if (0xa1 <= lastByte && lastByte <= 0xfe) {
// 1バイト目が0xa1〜0xfeの場合
if (0xa1 <= currByte && currByte <= 0xfe) {
// 2バイト目が0xa1〜0xfeならEUC-JP
return Encoding.GetEncoding("euc-jp");
}
}
// 断定出来ない場合は、次は1バイト目と見なして解析を続ける。
byteCount = 1;
}
else {
// 3バイト文字には対応していない
throw new NotSupportedException("3バイト文字には対応していません");
}
}
// 断定出来なかった場合
return Encoding.ASCII;
}